自從云計算的概念被提出,不斷地有IT廠商推出自己的云計算平臺。Amazon的AWS、微軟的Azure和IBM的藍云等都是云計算的典型代表,但它們都是商業性平臺,對于想要繼續研究和發展云計算技術的個人和科研團體說,無法獲得更多的了解,Hadoop的出現給研究者帶來了希望。本章將重點介紹Hadoop的HDFS、MapReduce和 jHBase,以及Hadoop的具體應用。
Hadoop簡介
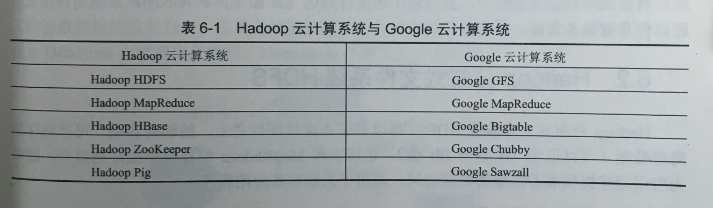
Hadoop是Apache開源組織的一個分布式計算框架,可以在大量廉價的硬件設備組成的集群上運行應用程序,為應用程序提供了一組穩定可靠的接口,旨在構建一個具有高靠性和良好擴展性的分布式系統。隨著云計算的逐漸流行,這一項目被越來越多的個人和企業所運用。Hadoop的核心是HDFS、MapReduce和HBase,它分別是Google云計算最核心技術GFS、MapReduce和Bigtable的開源實現(表6-1 )。
Hadoop源于另外兩個開源項目Lucene和Nutch,它們是一脈相承的關系。Lucene是一個用Java開發的開源高性能全文檢索工具包,可以很方便地嵌入到各種實際應用中,實現搜索/索引功能;Nutch是第一個開源的Web搜索引擎,它在Lucene的基礎上增加了網絡爬蟲、Web相關的一些功能及一些解析各類文檔格式的插件等,還包含一個分布式文件系統用于存儲數據。從Nutch 0.8.0開始,將其中實現分布式文件系統和MapReduce算法的代碼獨立出來,形成了一個新的開源項目,這就是HadooP。
Hadoop豐要由以下幾個子項目組成。
(1)Hadoop Common:即原來的Hadoop Core。這是整個Hadoop項目的核心,其他Hadoop子項目都是在Hadoop Common的基礎上發展的。
(2)Avro: Hadoop的RPC(遠程過程調用)方案。
(3)Chukwa:—個用來管理大型分布式系統的數據采集系統。
(4)HBase:支持結構化數據存儲的分布式數據庫,是Bigtable的開源實現。
(5)HDFS(Hadoop Distributed File System):提供髙吞吐量的分布式文件系統,是GFS的開源實現。
(6)Hive:提供數據摘要和查詢功能的數據倉庫。
(7)MapReduce:大型數據的分布式處理模型,是Google的MapReduce的開源實現。
(8)Pig:是在MapReduce上構建的一種高級的數據流語言,它是Sawzall的開源實現。Sawzall是一種建立在MapReduce基礎上的領域語言,它的程序控制結構(如if、 while等)與C語言無異,但它的領域語言語義使它完成相同功能的代碼比MapReduce的C++代碼簡潔得多。
(9)ZooKeeper:用于解決分布式系統中一致性問題,是Chubby的開源實現。
在這些子項目中,Pig最初是由Yahoo的網格部門開發的,后來捐獻給了Apache基金會。Awo和Chukwa剛加入不久,目前還不是很成熟。從實現的功能來看,Hadoop幾乎就是Google的一個“翻版”,幾乎每個子項目都是Google某項技術的開源實現。
除了是開源的之外,Hadoop還有很多優點。
(1)可擴展。不論是存儲的可擴展還是計算的可擴展都是Hadoop的設計根本。
(2)經濟。Hadoop可以運行在廉價的PC上。
(3)可靠。HDFS的備份恢復機制及MapReduce的任務監控機制保證了分布式處理的可靠性。
(4)高效。分布式文件系統的高效數據交互實現及MapReduce結合Local Data處理的模式,為高效處理海量的信息做了基礎準備。
目前此項目正在進行中,雖然現在還沒有到達1.0版本,和Google系統還有很大差距,但是前景非常好,值得我們關注。
