1.新服務部署中Dapper的使用
Google的AdWords系統的構建圍繞著一個由關鍵字命中準則和相關的文字廣告組成的大型數據庫。在這個系統進行重新開發時,開發團隊從原型系統直到最終版本的發布過程中,反復的使用了Dapper。開發團隊利用Dapper對系統的延遲情況進行一系列的跟蹤,進而發現存在的問題,最終證明Dapper對于AdWords系統的開發起到了至關重要的作用。
2.定位長尾延遲(Addressing Long Tail Latency)
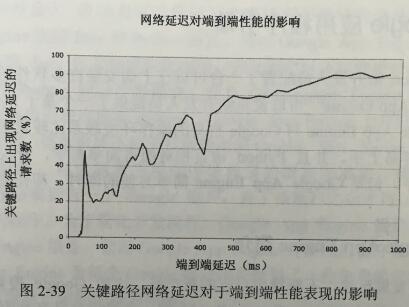
Google最重要的產品就是搜索引擎,由于規模龐大,對其進行調試是非常復雜的。當用戶請求的延遲過長,即延遲時間處于延遲分布的長尾時,即使最有經驗的工程師對這種端到端性能表現不好的根本原因也常常判斷錯誤。通過圖2-39不難發現,端到端性能和關鍵路徑上的網絡延遲有著極大的關系,因此發現關鍵路徑上的網絡延遲常常就能夠發現端到端性能表現不佳的原因。利用Dapper恰恰能夠比較準確的發現關鍵路徑。
3.推斷服務間的依存關系(Inferring Service Dependencies)
Google的后臺服務之間經常需要互相的調用,當出現問題時需要確定該時刻哪些服務是相互依存的,因為這樣有利于發現導致問題的真正原因。Google的“服務依存關系”項目使用監控注釋和DPAI的MapReduce接口實現了服務依存關系確定的自動化。
4.確定不同服務的網絡使用情況
在Dapper出現之前,Google的網管人員在網絡出現故障時幾乎沒有工具能夠確定到底是哪個部分的網絡出現的故障。而現在Google利用Dapper平臺構建了一個連續不斷更新的控制臺,用來顯示內部集群網絡通信中最活躍的應用層終端。這樣在出現問題時可以最快的定位占用網絡資源最多的幾個服務。
5.分層的共享式存儲系統
Google中的許多存儲系統都是由多個相對獨立且具有復雜層次的分布式基礎架構組成。例如,Google App Engine是構建在一個可擴展的實體存儲系統之上的。而該實體存儲系統則是構建在底層的Bigtable之上,展現出一些RDBMS (關系型數據庫管理系統)的功能。而Bigtable又依次用到了Chubby和GFS。在這樣的層次式系統中決定端用戶的資源消耗模式并不總是那么簡單。例如,由Bigtable的單元引起的GFS高流量可能主要由一個用戶或幾個用戶產生,但是在GFS的層次上這兩種不同的使用模式是沒法分開的。更進一步,在沒有Dapper之類的工具的情況下對于這種共享式服務資源的爭用也同樣難以調試。
6.利用Dapper進行“火拼”(Firefighting with Dapper)
這里所謂的“火拼”是指處于危險狀態的分布式系統的代表性活動。正在“火拼”中的Dapper用戶需要訪問最新的數據卻沒有時間來編寫新的DAPI代碼或者等待周期性的報告,此時可以通過和Dapper守護進程的直接通信,將所需的最新數據匯總在一起。
Dapper在Google內部取得了巨大的成功,雖然畢種成功在一定程度上得益于Google內部系統的同構性,但是Dapper團隊的創新性設計才是系統取得成功的根本性因素。Google的后臺系統可以說是目前全球最大的一個云平臺,讀者借鑒Dapper的設計思想一定能夠為不同規模的云平臺設計出合適的監控系統。
